学习NLP也有一段时间了,但一直没有时间对近年来NLP最出彩的attention部分加以总结,现在终于有一点时间可以做一下总结归纳了,那让我们顺着时间线,探寻attention的前世今生。
这事要从1930年9月7号开始说起,那年袁隆平爷爷出生在北京的一个普通家庭···
前世
1. Attention为什么这么受欢迎?
Attention是一种用于提升基于RNN(LSTM或GRU)的Encoder - Decoder模型的效果的的机制(Mechanism)。Attention Mechanism目前非常流行,广泛应用于机器翻译、语音识别、图像标注(等很多领域,之所以它这么受欢迎,是因为Attention给模型赋予了区分辨别的能力,例如,在机器翻译、语音识别应用中,为句子中的每个词赋予不同的权重,使神经网络模型的学习变得更加灵活,同时Attention本身可以做为一种对齐关系,解释翻译输入/输出句子之间的对齐关系,解释模型到底学到了什么知识,为我们打开深度学习的黑箱,提供了一个窗口。如下图所示:


通过上图,我们发现attention与人类的观察机制很相似,当人类观察外界事物的时候,一般不会把事物当成一个整体去看,往往倾向于根据需要选择性的去获取被观察事物的某些重要部分,因此,Attention Mechanism可以帮助模型对输入的X每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销,这也是Attention Mechanism应用如此广泛的原因。
2. Attention的提出
2014年,Ilya Sutskever等人在论文《Sequence to Sequence Learning with Neural Networks》中使用LSTM来搭建Seq2Seq模型。Seq2Seq模型基于一个Encoder和一个Decoder来构建基于神经网络的End-to-End的机器翻译模型,其中,Encoder把输入X编码成一个固定长度的隐向量Z,Decoder基于隐向量Z解码出目标输出Y。这是一个非常经典的序列到序列的模型。
其中,Encoder把一个变成的输入序列$x_1,x_2,x_3….x_t$编码成一个固定长度隐向量(背景向量,或上下文向量context)c,c有两个作用:1、做为初始向量初始化Decoder的模型,做为decoder模型预测y1的初始向量。2、做为背景向量,指导y序列中每一个step的y的产出。Decoder主要基于背景向量c和上一步的输出yt-1解码得到该时刻t的输出yt,直到碰到结束标志(< EOS>)为止。

但是这个模型却存在两个明显的问题:
1、把输入X的所有信息有压缩到一个固定长度的隐向量Z,忽略了输入输入X的长度,当输入句子长度很长,特别是比训练集中最初的句子长度还长时,模型的性能急剧下降。
2、把输入X编码成一个固定的长度,对于句子中每个词都赋予相同的权重,这样做是不合理的,比如,在机器翻译里,输入的句子与输出句子之间,往往是输入一个或几个词对应于输出的一个或几个词。因此,对输入的每个词赋予相同权重,这样做没有区分度,使得模型性能下降。
因此,2015年,Kyunghyun Cho等人在论文《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》中,引入了Attention Mechanism来解决这个问题,他们提出的模型结构如下图所示。

定义条件概率:
其中Si是RNN在时间点i的隐状态,可表示为:
这里的背景向量ci的计算方式,与传统的Seq2Seq模型直接累加的计算方式不一样,这里的ci是一个权重化(Weighted)之后的值,考虑了不同词之前的权重和影响程度。其中权重的计算采用了对齐模型(dot product),对齐模型不同的计算方式,代表不同的Attention模型。
具体计算可见《NEURALMACHINETRANSLATIONBYJOINTLYLEARNING TOALIGN ANDTRANSLATE》。
今生
此后,attention登上历史舞台,不同种类的attention mechanism,在不同任务中均起到了提升效果。下面介绍不同种类的attention,并针对NLP任务进行分析。
1. Attention的分类
1.1 Soft Attention & Hard Attention
Kelvin Xu等人与2015年发表论文《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》,在Image Caption中引入了Attention,当生成第i个关于图片内容描述的词时,用Attention来关联与i个词相关的图片的区域。Kelvin Xu等人在论文中使用了两种Attention Mechanism,即Soft Attention和Hard Attention。我们之前所描述的传统的Attention Mechanism就是Soft Attention。Soft Attention是参数化的(Parameterization),因此可导,可以被嵌入到模型中去,直接训练。梯度可以经过Attention Mechanism模块,反向传播到模型其他部分。
相反,Hard Attention是一个随机的过程。Hard Attention不会选择整个encoder的输出做为其输入,Hard Attention会依概率$S_i$来采样输入端的隐状态一部分来进行计算,而不是整个encoder的隐状态。为了实现梯度的反向传播,需要采用蒙特卡洛采样的方法来估计模块的梯度。
两种Attention Mechanism都有各自的优势,但目前更多的研究和应用还是更倾向于使用Soft Attention,因为其可以直接求导,进行梯度反向传播。
1.2 Global Attention & Local Attention
Global Attention:和传统attention一样, 所有的hidden state都被用于计算Context vector 的权重,即变长的对齐向量 ,其长度等于encoder端输入句子的长度。

在t时刻,首先基于decoder的隐状态$h_t$和源端的隐状态$h_s$计算一个变长的隐对齐权值向量at,其计算公式如下:
其中,score是一个用于评价ht与hs之间关系的函数,即对齐函数,一般有三种计算方式:
Local Attention:Global Attention有一个明显的缺点就是,每一次,encoder端的所有hidden state都要参与计算,这样做计算开销会比较大,特别是当encoder的句子偏长,比如,一段话或者一篇文章,效率偏低。因此,为了提高效率,Local Attention应运而生。

Local Attention首先会为decoder端当前的词,预测一个source端对齐位置(aligned position),然后基于$p_t$选择一个窗口,用于计算背景向量 。其中$a_t$为对齐向量:
在实际应用中,global Attention应用更普遍,因为local Attention需要预测一个位置向量p,这就带来两个问题:
1、当encoder句子不是很长时,相对Global Attention,计算量并没有明显减小。
2、位置向量pt的预测并不非常准确,这就直接计算的到的local Attention的准确率。
1.3 Attention本质思想

如上图所示,attention将Source中的构成元素想象成是由一系列的
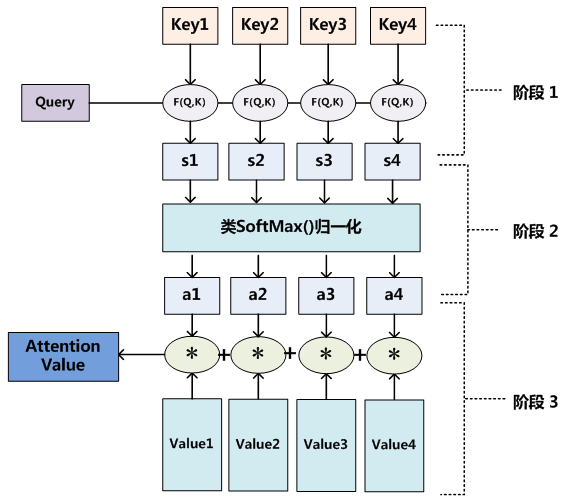
另外一种理解是,可以将Attention机制看作一种软寻址:Source可以看作存储器内存储的内容,元素由地址Key和值Value组成,当前有个Key=Query的查询,目的是取出存储器中对应的Value值,即Attention数值。通过Query和存储器内元素Key的地址进行相似性比较来寻址,之所以说是软寻址,指的不像一般寻址只从存储内容里面找出一条内容,而是可能从每个Key地址都会取出内容,取出内容的重要性根据Query和Key的相似性来决定,之后对Value进行加权求和,这样就可以取出最终的Value值,也即Attention值。所以不少研究人员将Attention机制看作软寻址的一种特例,这也是非常有道理的。
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为如下图展示的三个阶段:
1.4 self-attention
2018年,《attention is all you need》横空出世,到那时为止,对Attention层的描述都是一般化的,Transformer的提出将attention进行了机器翻译的应用。
所谓Self Attention,其实就是Attention(X,X,X) , 就是前面说的输入序列。也就是说,在序列内部做Attention,寻找序列内部的联系。此论文的主要贡献之一是它表明了内部注意力在机器翻译(甚至是一般的Seq2Seq任务)的序列编码上是相当重要的,而之前关于Seq2Seq的研究基本都只是把注意力机制用在解码端。类似的事情是,目前SQUAD阅读理解的榜首模型R-Net也加入了自注意力机制,这也使得它的模型有所提升。
当然,更准确来说,Google所用的是Self Multi-Head Attention:

self attention中,Q,K,V分别来自同一个sequence的映射。
为什么说是Multi-Head呢?在transformer中,Encoder和decoder是层叠多了类似的Multi-Head Attention单元构成,而每一个Multi-Head Attention单元由多个结构相似的Scaled Dot-Product Attention单元(上图)组成。


至此,transformer的核心已经讲出,再经过正则化和RNN,便可得到transformer框架:

1.5 Attention其他一些组合使用
1. Hierarchical Attention
2. Attention over Attention
3. Multi-step Attention
4. Multi-dimensional Attention
5. Memory-based Attention

