Graph Embedding 目前已经在深度学习很多领域取得很好的成绩。目前,Graph Embedding是推荐系统、计算广告领域最近非常流行的做法,是从word2vec等一路发展而来的Embedding技术的最新延伸,并且很多大厂已经用Graph Embedding 取得了很好的效果。
word2vec和由其衍生出的item2vec是embedding技术的基础性方法,但二者都是建立在“序列”样本(比如句子、推荐列表)的基础上的。而在互联网场景下,数据对象之间更多呈现的是图结构。典型的场景是由用户行为数据生成的和物品全局关系图(图1),以及加入更多属性的物品组成的知识图谱(图2)。

在面对图结构的时候,传统的序列embedding方法就显得力不从心了。在这样的背景下,对图结构中间的节点进行表达的graph embedding成为了新的研究方向,并逐渐在深度学习推荐系统领域流行起来。
经典方法1 —DeepWalk
早期影响力较大的graph embedding是2014年的DeepWalk,其主要思想是在由节点组成的图上随机游走,产生大量节点序列,然后将这些序列作为训练样本进行word2vec,得到embedding

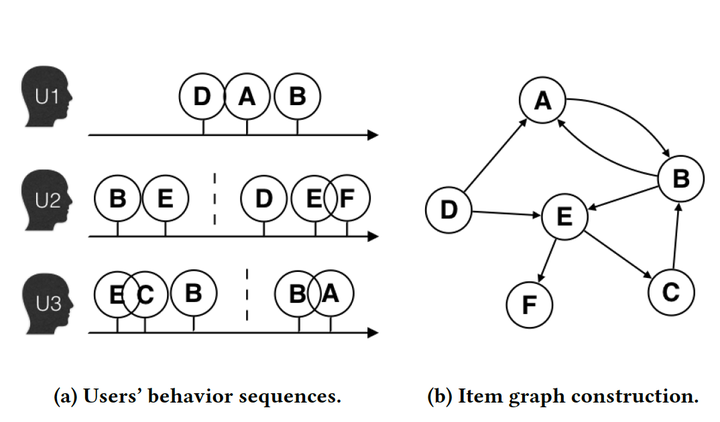
如上图所示,整个DeepWalk可以分为四个过程:
- 图a展示了原始的用户行为序列
- 图b基于这些用户行为序列构建了物品相关图,可以看出,物品A,B之间的边产生的原因就是因为用户U1先后购买了物品A和物品B,所以产生了一条由A到B的有向边。如果后续产生了多条相同的有向边,则有向边的权重被加强。在将所有用户行为序列都转换成物品相关图中的边之后,全局的物品相关图就建立起来了。
- 图c采用随机游走的方式随机选择起始点,重新产生物品序列。
- 图d最终将这些物品序列输入word2vec模型,生成最终的物品Embedding向量。
在整个算法流程中,核心是第三步,对随机游走的跳转概率进行明确定义,即到达节点$v_i$后,下一步遍历$v_i$的临接点$v_j$的概率。如果物品的相关图是有向有权图,那么从节点$v_i$跳转到节点$v_j$的概率定义如下:

其中$N+(v_i)$是节点$v_i$所有的出边集合,$M{ij}$是节点$v_i$到节点$v_j$边的权重。
如果物品相关图是无相无权重图,那么跳转概率将是上面公式的一个特例,即权重$M{ij}$将为常数1,且$N+(v_i)$应是节点$v_i$所有“边”的集合,而不是所有“出边”的集合。
DeepWalk的改进 — Node2Vec
2016年,斯坦福大学在DeepWalk的基础上更进一步,通过调整随机游走权重的方法使graph embedding的结果在网络的同质性(homophily)和结构性(structural equivalence)中进行权衡权衡。
具体来讲,网络的“同质性”指的是距离相近节点的embedding应该尽量近似,如下图,节点u与其相连的节点s1、s2、s3、s4的embedding表达应该是接近的,这就是“同质性“的体现。
“结构性”指的是结构上相似的节点的embedding应该尽量接近,图中节点u和节点s6都是各自局域网络的中心节点,结构上相似,其embedding的表达也应该近似,这是“结构性”的体现。

为了让Graph Embedding的结果更能表达同质性,在游走过程中需要更倾向于DFS,因为DFS更喜欢走到跟当前节点有直接相连的节点上,从而被embedding表达;另一方面,为了抓住网络的结构性,需要随机游走更倾向于BFS,这样会使生成的样本序列包含网络整体信息。
在node2vec算法中。主要是通过节点间的跳转概率控制BFS和DFS的倾向性。下图表示了从节点t跳转到节点v后,下一步从节点v跳转到周围各点的跳转概率。

形式化来讲。从节点v跳到下一个节点x的概率为

其中 是边vx的权重,
的定义如下

其中$d_{tx}$指的是t到x节点的距离,参数p和q共同控制随机游走倾向性,参数p被称为返回参数(return parameter),p越小,随机游走回节点t的可能性越大,node2vec就更注重表达网络的结构性,参数q被称为进出参数(in-out parameter),q越小,则随机游走到远方节点的可能性越大,node2vec更注重表达网络的同治性,反之,当前节点更可能在附近节点游走。
node2vec这种灵活表达同质性和结构性的特点也得到了实验的证实。图6的上图就是node2vec更注重同质性的体现,可以看到距离相近的节点颜色更为接近,而图6下图则是结构特点相近的节点的颜色更为接近。

node2vec所体现的网络的同质性和结构性在推荐系统中也是可以被很直观的解释的。同质性相同的物品很可能是同品类、同属性、或者经常被一同购买的物品,而结构性相同的物品则是各品类的爆款、各品类的最佳凑单商品等拥有类似趋势或者结构性属性的物品。毫无疑问,二者在推荐系统中都是非常重要的特征表达。由于node2vec的这种灵活性,以及发掘不同特征的能力,甚至可以把不同node2vec生成的embedding融合共同输入后续深度学习网络,以保留物品的不同特征信息。
Deepwalk的补充 — EGES
2018年,阿里公布了其在淘宝应用的Embedding方法EGES(Enhanced Graph Embedding with Side Information),其基本思想是在DeepWalk生成的graph embedding基础上引入补充信息。
如果单纯使用用户行为生成的物品相关图,固然可以生成物品的embedding,但是如果遇到新加入的物品,或者没有过多互动信息的长尾物品,推荐系统将出现严重的冷启动问题。为了使“冷启动”的商品获得“合理”的初始Embedding,阿里团队通过引入了更多补充信息来丰富Embedding信息的来源,从而使没有历史行为记录的商品获得Embedding。
生成Graph embedding的第一步是生成物品关系图,通过用户行为序列可以生成物品相关图,利用相同属性、相同类别等信息,也可以通过这些相似性建立物品之间的边,从而生成基于内容的knowledge graph。而基于knowledge graph生成的物品向量可以被称为补充信息(side information)embedding向量,当然,根据补充信息类别的不同,可以有多个side information embedding向量。
side information是从用户行为建模中得来,在DeepWalk中我们可以生成很多序列,接着,我们使用Skip-Gram算法来学习embeddings,他会最大化在获取序列的两个节点的共现概率。这会生成以下优化问题:
其中,w是在序列中上下文节点的window size。使用独立假设,我们具有:
通过以上embedding方法, 我们就可以得到淘宝中所有商品的embedding,来捕获在用户行为序列上的更高阶相似度,这种特性会被基于CF的方法忽略。然而,对于“冷启动(cold-start)”的items,学到精准的embeddings仍然是个挑战。所以淘宝提出了GES方法:

在GES中的深度神经网络中加入average pooling层将不同embedding平均起来,这样就能获得更好的Embedding,阿里在此基础上进行了加强,对每个embedding加上了权重,如上图所示,对每类特征对应的Embedding向量,分别赋予了权重$a_0,a_1…a_n$ ,图中的Hidden Representation层就是对不同Embedding进行加权平均操作的层,得到加权平均后的Embedding向量后,再直接输入softmax层,这样通过梯度反向传播,就可以求的每个embedding的权重$a_i$(i=0…n)
在实际的模型中,阿里采用了 而不是$a_j$作为相应embedding的权重,一是避免权重为0,二是因为
在梯度下降过程中有良好的数学性质。

阿里的EGES并没有过于复杂的理论创新,但给出一个工程性的结合多种Embedding的方法,降低了某类Embedding缺失造成的冷启动问题,是实用性极强的Embedding方法。
最后
近些年中,KGE又与GAN结合起来,提高了KGE的效率,代表有KBGAN等,在以后的博文中我会详细介绍。

